

Diagnosing the Gap: Why Demos Don't Scale
The journey from a laptop prototype to a deployed application is rarely linear, yet many teams treat it as a simple deployment step. The reality is that a Proof of Concept (POC) is a controlled experiment, while production is a hostile ecosystem. The primary reason AI pilots fail to launch is not usually the capability of the model itself, but the lack of scaffolding required to support it.
This phenomenon was effectively categorized by Google researchers in their seminal paper on "Hidden Technical Debt in Machine Learning Systems." They demonstrated that the actual machine learning code is only a tiny fraction of the deployed system. The vast majority of the engineering effort lies in the surrounding infrastructure—configuration, data collection, serving infrastructure, and monitoring. When teams rush to production, they often bring the model but leave the necessary operational discipline behind.
Furthermore, demos are built on the "Happy Path." During a presentation, inputs are curated, the context is perfect, and the system is under zero load. Production environments, however, are chaotic. A robust system must handle a barrage of issues that a sanitized demo never encounters:
- Edge Cases: Real users submit ambiguous, poorly formatted, or adversarial inputs that break fragile prompts.
- Latency Spikes: A five-second response time might be acceptable in a boardroom meeting, but it destroys user retention in a live consumer app.
- Security Vulnerabilities: Demos rarely account for prompt injection attacks or the accidental leakage of Personally Identifiable Information (PII).
Finally, the most dangerous trap is the reliance on "vibe checks" for quality assurance. Simply reading a few model outputs and deciding they "feel right" is not a testing strategy. Without systematic evaluation—using quantitative metrics to measure accuracy, hallucination rates, and recall—you are flying blind. You cannot safely scale what you do not rigorously measure.

Architecting for Reliability: The MLOps Pipeline
In the experimentation phase, a Jupyter Notebook is an invaluable canvas for rapid iteration and immediate feedback. However, treating a notebook as a production artifact is one of the most common reasons AI initiatives stall. To escape pilot purgatory, you must shift your focus from optimizing the model to optimizing the pipeline that delivers it. This requires refactoring experimental spaghetti code into modular, testable scripts integrated into a robust Continuous Integration/Continuous Deployment (CI/CD) workflow. By automating testing and deployment, you ensure that changes to the model or data processing logic are validated systematically before they ever touch a live environment.
Reliability also hinges on consistent execution environments. The classic developer defense—"it worked on my machine"—is unacceptable in enterprise AI. Containerization, primarily through Docker, encapsulates your model and its dependencies into a portable unit that behaves identically in development, staging, and production. When traffic surges, orchestrating these containers with Kubernetes provides the elasticity needed to scale horizontally, ensuring high availability without manual intervention.
Furthermore, the rise of Generative AI introduces a new artifact that requires strict governance: the prompt. Adopting "Prompt Engineering as Code" is essential for maintaining control over system behavior. Rather than burying prompt strings inside application code or database columns, you should treat them as versioned software assets. A mature MLOps strategy for LLMs includes:
- Version Control: Storing prompts in Git repositories to track history and authorship.
- Immutability: Ensuring that specific prompt versions are tied to specific model versions for reproducibility.
- Rollback Capabilities: The ability to instantly revert to a previous prompt version if a new iteration degrades output quality or introduces hallucinations.
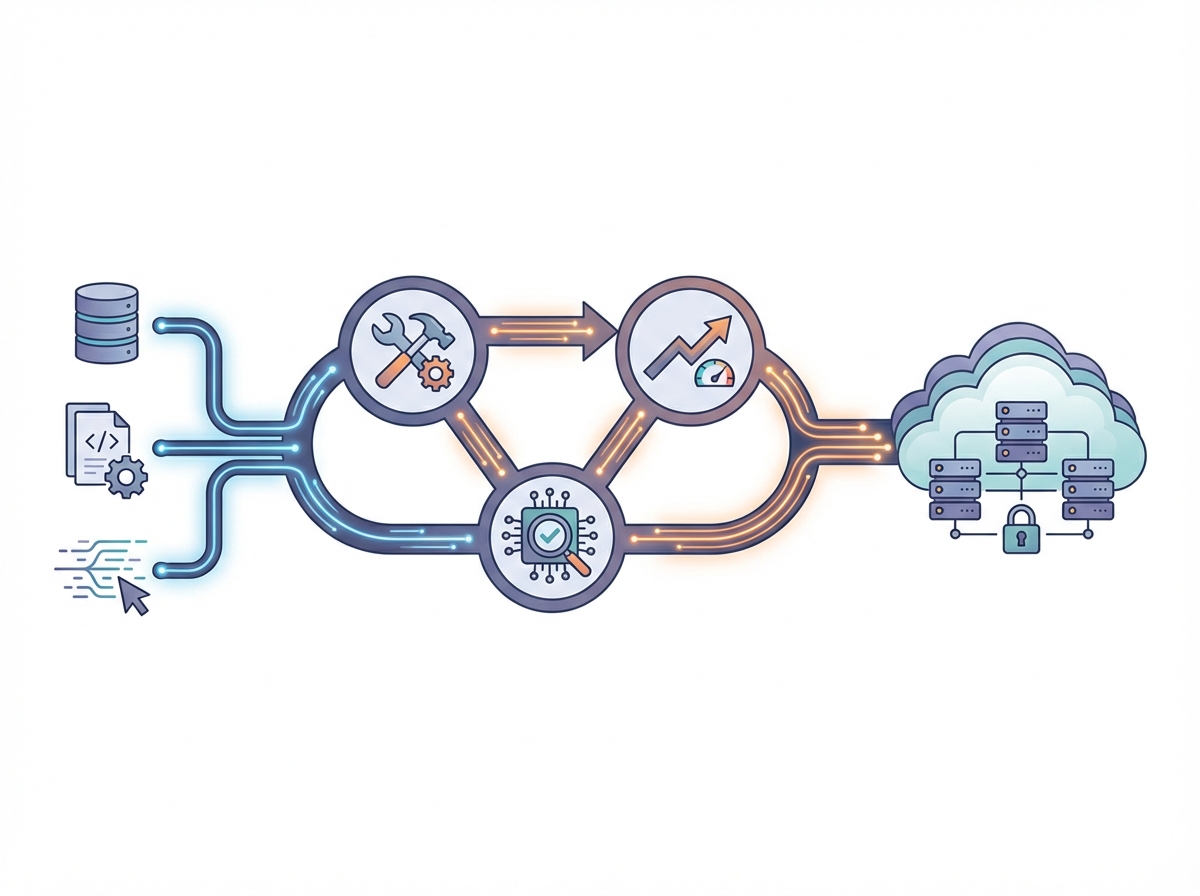
Continuous Evaluation and Observability
Many teams pop the champagne the moment their AI application hits the production environment, but in the world of generative AI, deployment is not the finish line—it is merely the starting gun. Unlike deterministic code, LLMs are probabilistic; they can drift, hallucinate, or behave unexpectedly as user inputs evolve. Escaping pilot purgatory requires acknowledging that your system will degrade over time unless you actively monitor and tune it.
Reliability starts with robust Evals. You cannot improve what you cannot measure. To ensure stability, you need to curate a "golden dataset"—a comprehensive set of input examples and ideal responses that represent your core use cases. Before every prompt update or model swap, your system must automatically run against this dataset. This practice acts as a regression test, guaranteeing that an optimization for one feature doesn't inadvertently break the accuracy of another.
Once the model is serving real traffic, traditional application monitoring isn't enough. You need observability metrics specifically designed for AI workloads:
- Token Usage and Cost Tracking: Monitor input versus output tokens granularly. A sudden spike in usage often indicates a prompt injection attack or an inefficient looping mechanism.
- Latency Drift: AI responses take time, but inconsistency kills user trust. Track time-to-first-token (TTFT) and total generation time to spot infrastructure bottlenecks immediately.
- Response Quality Monitoring: Since manual review of every log is impossible, adopt an "LLM-as-a-Judge" approach. Use a stronger, more capable model to grade a sample of your production model's outputs for accuracy, tone, and safety, alerting you when quality dips below a defined threshold.

The Guardrails: Deterministic Controls for Probabilistic Models
Large Language Models (LLMs) are, by definition, stochastic engines. They function as advanced pattern-matchers that roll the dice to predict the next token based on statistical likelihood. While this probabilistic nature fuels creativity, it acts as the enemy of reliability in a production environment. To move beyond the pilot stage, you must stop treating the LLM as a magical oracle and start treating it as an untrusted component that requires strict supervision. The secret to stable production AI is wrapping the probabilistic model in layers of deterministic logic.
Reliability usually stems from restricting the model's freedom. By implementing robust guardrails, you create a bounded environment where the AI can operate safely without hallucinating facts or outputting harmful content. Three critical strategies form the backbone of this deterministic wrapper:
- Structured Output Parsing: Never rely on an LLM to generate raw text that your application logic then tries to parse with regular expressions. Instead, enforce strict output schemas, such as JSON. By compelling the model to adhere to a specific structure, you transform vague natural language into executable data, preventing downstream errors when the model inevitably changes its phrasing.
- Safety and Constitutional Checks: Implement a validation layer that sits between the model and the user. Drawing on principles of "Constitutional AI," this layer programmatically evaluates both inputs and outputs against a set of safety rules. If a response detects a policy violation or a hallucination, the guardrail intercepts it and triggers a fallback mechanism before the user ever sees the error.
- Semantic Caching: One of the best ways to control costs and latency is to avoid calling the LLM altogether. Semantic caching stores previous queries and their responses. When a user asks a question that is semantically similar to a previous one, the system retrieves the answer from the cache. this turns a slow, expensive, probabilistic generation into a fast, cheap, and deterministic lookup.
Ultimately, escaping pilot purgatory requires a shift in architecture. You are not building a chatbot; you are building a software system where the AI is merely a sub-routine. By minimizing the surface area of randomness through these guardrails, you ensure that your application behaves predictably, even when the underlying model does not.


