

The 'Transpiler' Trap: Why Syntax Conversion Isn't Enough
For many organizations, legacy modernization starts with a deceptively simple goal: get off the mainframe. To achieve this, IT leaders often turn to automated transpilers designed to translate code line-by-line from archaic languages like COBOL or Fortran into modern counterparts like Java or C#. While this approach offers speed, it frequently leads to a deceptive outcome known as the 'Transpiler Trap.'
A direct, 1:1 translation preserves the logic structure of the original program. Consequently, forty-year-old 'spaghetti code'—riddled with GOTO statements, global variables, and monolithic dependencies—is merely replicated in a modern syntax. The result is often referred to derisively as 'JOBOL' (Java written as COBOL). The application may compile on a modern server, but it remains brittle, difficult to test, and nearly impossible for modern developers to maintain without deciphering the original legacy mindset.
To avoid creating unmaintainable modern code, businesses must distinguish between two critical outcomes:
- Semantic Equivalence: This ensures the new code produces the exact same output as the old code. While necessary for functional correctness, relying on this alone retains the obsolete architecture.
- Architectural Improvement: This involves refactoring the code to utilize modern paradigms, such as object-oriented design, functional programming, and a clean separation of concerns.
If the goal is to actually reduce technical debt rather than just shifting it to a new file extension, syntax conversion is insufficient. True modernization requires structural refactoring that transforms the underlying architecture, making the system modular, readable, and scalable for the future.
Defining Agentic AI in the Context of Code
To understand the true potential of Agentic AI in legacy modernization, we must first distinguish it from the standard generative coding assistants that have become ubiquitous. Tools like GitHub Copilot or standard LLM interfaces function primarily as advanced autocomplete engines. They are passive tools that rely on the immediate context provided by the developer—usually the currently open file or a specific prompt—to predict the next likely snippet of syntax.
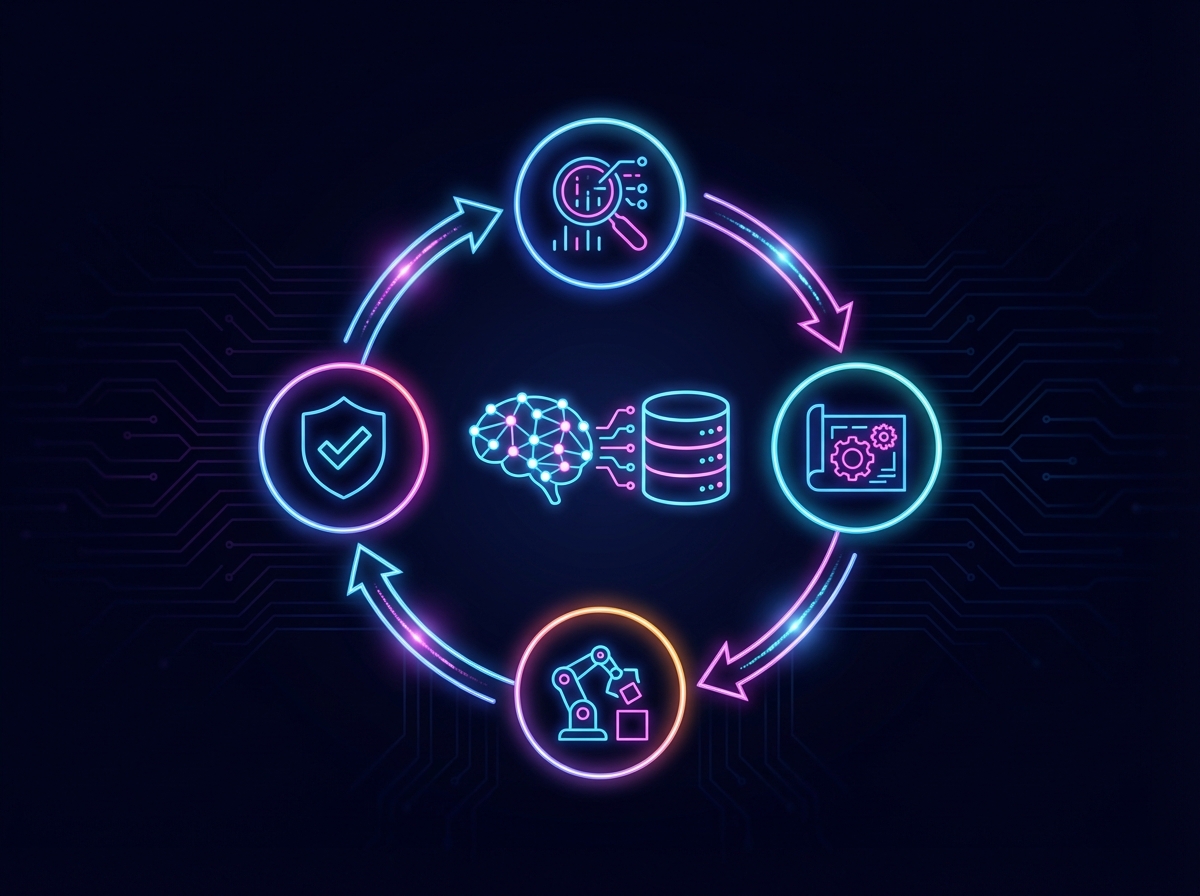
Agentic AI, by contrast, operates as an autonomous entity designed to pursue high-level engineering objectives rather than merely completing patterns. In the context of software engineering, an "agent" does not just suggest code; it navigates the repository to execute a continuous cognitive cycle. This shifts the paradigm from simple code generation to actual problem solving, powered by a distinct feedback loop:
- Perception: The agent actively scans the codebase, reading beyond the current file to identify directory structures, configuration settings, and cross-module references.
- Reasoning: It maps dependencies and logic flows to build a dynamic plan, determining how a change in one legacy module will impact the broader architecture.
- Action: The agent executes structural refactoring, capable of creating new files, moving classes, and rewriting logic rather than just appending lines.
- Observation: Crucially, the agent acts on its own output. It runs compilers, executes unit tests, and reads error logs to validate the success of its actions.
This capacity for Observation is the differentiator. If a standard coding assistant suggests code that breaks the build, the human developer must fix it. An AI agent, however, detects the failure, adjusts its approach, and retries. By autonomously exploring the codebase to build a comprehensive mental model of the system, Agentic AI can disentangle the complex, undocumented dependencies often found in legacy applications, treating modernization as an iterative engineering task rather than a one-shot translation.
Guardrails and Governance: The Human Architect's Role
Unleashing autonomous agents on a legacy codebase offers immense speed, but it introduces a distinct set of risks. Unlike simple code translation, structural refactoring requires deep context. Without oversight, an AI agent might hallucinate a dependency that doesn’t exist or inadvertently refactor away a critical, undocumented edge case that holds a specific business process together.
This reality forces a fundamental pivot in the human developer's role. Instead of functioning primarily as writers of syntax, engineers evolve into architects and rigorous reviewers. They define the intent and strategy, leaving the execution to the AI. This shift demands a robust governance framework to ensure that autonomous refactoring enhances system stability rather than introducing subtle, hard-to-trace bugs.
To safely integrate Agentic AI into modernization workflows, organizations must establish three critical guardrails:
- Automated Test Generation (TDD): Agents should never modify code without a safety net. The workflow must prioritize Test-Driven Development, where the agent generates—and passes—comprehensive unit and integration tests before proposing a refactor.
- Sandbox Environments: Agents need a contained playground. By utilizing ephemeral sandbox environments, agents can experiment with architectural changes and run regression suites without threatening the stability of the main development branch.
- Strict Approval Gates: While agents can propose structural changes, they should not merge them. A human architect must act as the final gatekeeper, reviewing the logic, strategy, and test coverage to ensure the refactor aligns with long-term system goals.

From Logic Extraction to Microservices: The Workflow
Transforming a monolithic application requires more than a simple lift-and-shift approach; it demands a strategic dismantling of the old to build the new. Agentic AI automates this complex process by treating the legacy codebase as a dataset to be mined, analyzed, and refactored. Unlike static code converters, autonomous agents execute a multi-stage workflow to derive meaning before generating syntax.
Here is a step-by-step breakdown of how an agent dissects a monolith:
- Business Logic Extraction: Before writing a single line of modern code, the agent identifies the "why" behind the existing logic. It sifts through decades of patches and workarounds to isolate pure business rules—such as interest rate calculations or inventory validation—separating the core intent from the outdated infrastructure constraints that originally surrounded it.
- Dependency Mapping: Legacy systems are notorious for their tight coupling. The agent scans the codebase to generate a dynamic visualization of the "blast radius" for any given function. By mapping shared database tables, global variables, and cross-program calls, it reveals the tangled web of dependencies that must be untangled to ensure a clean break.
- Pattern Matching: Once dependencies are mapped, the agent looks for architectural seams. It applies domain-driven design principles to recognize where a monolithic subroutine acts like an independent service. It identifies specific clusters of logic that are prime candidates for decoupling into standalone microservices or event-driven serverless functions.
- Code Generation: Finally, the agent moves to synthesis. Rather than performing a line-by-line translation, it generates new, optimized code structures in the target language. This includes setting up necessary API endpoints, defining data contracts, and implementing modern error handling, effectively re-platforming the logic into a cloud-native ecosystem.


